计算机科学家经常使用图形来表示数据 。图可以表示各种关系,从地图和化合物到社会关系和计算机网络 。我们可以对图使用许多算法,例如Dijkstra 算法、深度优先搜索 (DFS)算法和广度优先搜索(或 BFS)算法 。虽然您可以使用这两种算法来遍历图的节点,但 BFS 更适合未加权的图 。在本文中,我们将探讨 BFS 的工作原理及其应用 。

文章插图
什么是 BFS?BFS 是一种搜索算法 。该算法从源节点开始遍历,然后访问相邻节点 。在此之后,算法选择下一个深度级别的最近节点,然后访问下一个未探索的节点,依此类推 。由于 BFS 算法在进入下一层之前会访问每一层的节点,这就是“广度优先”这个名称的由来 。我们通过跟踪已访问和未访问的节点来确保我们只访问每个节点一次 。您可以使用 BFS 来计算路径距离,就像使用 Dijkstra 算法一样 。
BFS背后的算法我们可以用以下伪代码表示基本算法:
BFS(图形,开始):队列 = [开始]已访问 = 设置(开始)当队列不为空时:节点=出队(队列)进程(节点)对于 graph.neighbors(node) 中的邻居:如果邻居不在访问中:visited.add(邻居)排队(队列,邻居)在这种情况下,我们将图定义为“graph”,“start”是起始节点 。
我们实现了一个队列结构来保存未访问的节点,以及一个“已访问”集来保存已访问的节点 。
“while”循环一直持续到队列为空,并开始逐级处理节点 。“dequeue”函数在第一个节点被访问时将其从队列中移除 。
“处理”功能在节点上执行一些所需的功能,例如更新到其邻居的距离或将数据打印到控制台 。
“for”循环遍历当前节点的所有邻居,检查该节点是否已经被访问过 。如果不是,则使用“enqueue”函数将其添加到队列中 。本质上,每个级别的节点都存储在队列中,并添加它们的邻居以在下一个深度级别访问 。这使我们能够确定源节点与图中每个其他节点之间的最短路径 。
BFS 的工作
文章插图
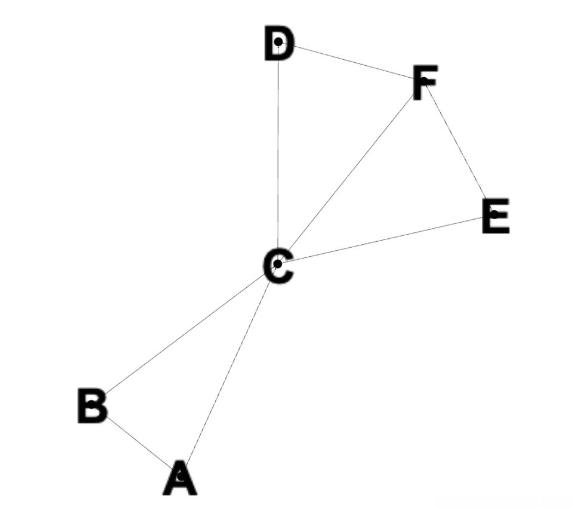
我们将在以下代码示例中使用此图 。
解释完基础知识后,是时候看看 BFS 在实践中是如何工作的了 。我们将使用具有节点 A、B、C、D、E 和 F 的图形来说明这一点,如图所示 。下面的代码展示了如何使用Python 编程语言为这个图实现 BFS。
从集合导入 defaultdict,双端队列def bfs(图形,开始):queue = deque([开始])已访问 = 设置([开始])排队时:节点 = queue.popleft()打印(节点)对于图[节点]中的邻居:如果邻居不在访问中:visited.add(邻居)queue.append(邻居)图=默认字典(列表)边缘= [(“A”,“B”),“A”,“C”),(“B”,“C”),(“C”,“D”),(“C”,“E” ), ("C", "F"), ("D", "F"), ("E", "F")对于边中边:图[边[0]].append(边[0])图[边[1]].append(边[0])bfs(图,“A”)守则说明首先,我们从“collections”模块导入“defaultdict”和“deque”类 。这些用于创建具有默认键值的字典,并创建允许添加和删除元素的队列 。
接下来,我们使用两个参数“graph”和“start”定义“bfs”函数 。我们将“图”参数作为一个字典,其中顶点作为键,相邻顶点作为值 。这里,“开始”指的是算法开始的源节点 。
“queue = deque([start])”创建一个以源节点为唯一元素的队列,“visited = set([start])”创建一组以源节点为唯一元素的已访问节点 。
“while”循环一直持续到队列为空 。“node = queue.popleft()”从队列中移除最左边的元素并将其存储在“node”变量中 。“print(node)”打印这些节点值 。
“for”循环遍历每个邻居节点 。“if neighbor not visited”检查邻居是否被访问过 。“visited.add(neighbor)”将邻居添加到访问列表,“queue.append(neighbor)”将邻居添加到队列的右端 。
在此之后,我们创建一个名为“graph”的默认字典,并定义图的边 。“for”循环遍历每条边 。“graph[edge[0]].append(edge[1])”将边的第二个元素添加为第一个元素的邻居,并将边的第一个元素添加为第二个元素的邻居 。这构建了图形 。
最后,我们在“graph”上调用“bfs”函数,源节点为“A” 。
代码的实现
文章插图
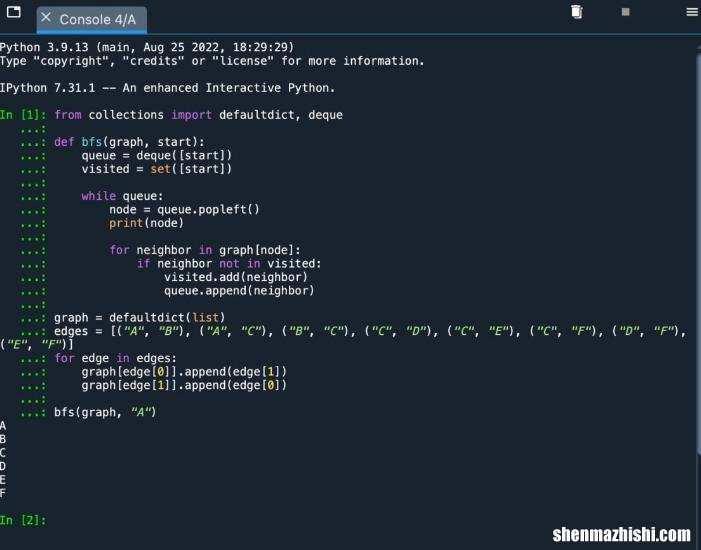
这就是 BFS 算法在通过连通图实现和运行时的样子 。
在屏幕截图中,我们可以看到输出 [A, B, C, D, EF] 。这是我们所期望的,因为 BFS 在移动到下一个深度级别之前探索每个深度级别的节点 。回顾图表,我们看到 B 和 C 将被添加到队列中并首先被访问 。访问了 B,然后将 A 和 C 添加到队列中 。由于已经访问过 A,接下来访问 C,然后删除 A 。此后,C 的邻居 D、E 和 F 被添加到队列中 。然后访问这些,并打印输出 。
对断开连接的图使用 BFS我们之前将 BFS 用于连通图 。但是,当节点未全部连接时,我们也可以使用 BFS 。我们将使用相同的图表数据,因为修改后的算法可以用任何一种图表来说明 。修改后的代码是:
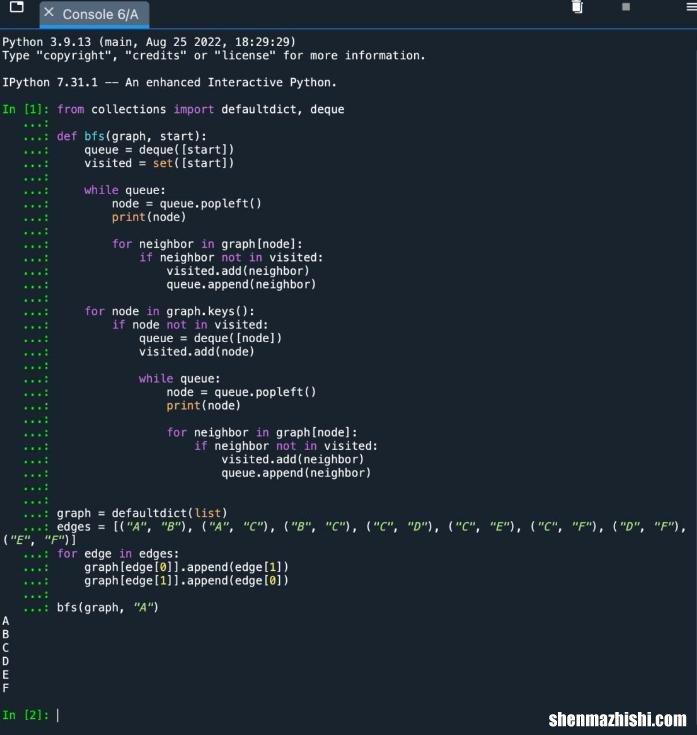
从集合导入 defaultdict,双端队列def bfs(图形,开始):queue = deque([开始])已访问 = 设置([开始])排队时:节点 = queue.popleft()打印(节点)对于图[节点]中的邻居:如果邻居不在访问中:visited.add(邻居)queue.append(邻居)对于 graph.keys() 中的节点:如果节点未被访问:queue = deque([节点])visited.add(节点)排队时:节点 = queue.popleft()打印(节点)对于图[节点]中的邻居:如果邻居不在访问中:visited.add(邻居)queue.append(邻居)图=默认字典(列表)边缘= [(“A”,“B”),(“A”,“C”),(“B”,“C”),(“C”,“D”),(“C”,“E "), ("C", "F"), ("D", "F"), ("E", "F")]对于边中边:图[边[0]].append(边[1])图[边[1]].append(边[0])bfs(图,“A”)我们使用了一个额外的“for”循环 。循环使用“graph.keys()”方法遍历所有节点 。如果 BFS 找到一个未访问的节点并递归工作,它会启动一个新队列 。通过这样做,我们访问了所有断开连接的节点 。有关说明,请参见下图 。
文章插图
BFS 的最佳和最差用例现在我们知道 BFS 是如何工作的,我们应该查看算法的时间和空间复杂度,以了解其最佳和最差用例 。
BFS 的时间复杂度
文章插图
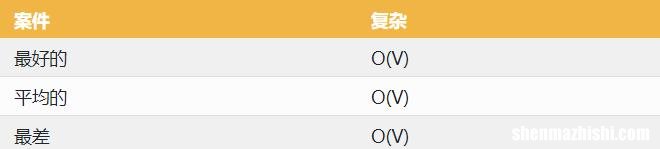
同样,我们看到所有情况的复杂性都是相同的 。无论图形结构如何,该算法都会访问每个节点 。因此,复杂度取决于图中的顶点数 。
BFS 是遍历图中节点、计算路径距离和探索节点之间关系的一种方法 。它是探索网络系统和检测图循环的非常有用的算法 。BFS 对于连通图和非连通图都相对容易实现 。一个好处是所有情况下的时间和空间复杂度都相同 。
图的广度优先搜索 (BFS),常见问题解答什么是 BFS?
BFS 是一种用于遍历树或图的算法,通常是那些代表社交网络或计算机网络的网络 。它还可以检测图循环或图是否是二分图,以及计算最短路径距离 。广度优先意味着在移动到下一个节点之前,在特定深度级别探索每个节点 。
BFS的时间复杂度是多少?
BFS 的时间复杂度在所有情况下都是 O(V + E) 。
BFS 的空间复杂度是多少?
BFS 的空间复杂度在所有情况下都是 O(V) 。
什么时候应该使用 BFS?
如果您需要计算最短路径距离,或探索未加权图中的所有顶点 。
BFS 是如何实现的?
我们通常使用队列数据结构和一个集合来实现 BFS,以跟踪已访问和未访问的节点 。源节点被添加到队列中并标记为已访问 。然后,该算法递归地对相邻节点进行操作,添加和删除节点,以确保没有节点被访问两次 。
BFS 与 Dijkstra 算法相比如何?
这些算法都可用于计算最短路径距离,但 BFS 适用于未加权的图 。相反,Dijkstra 算法适用于加权图 。
DFS 与 BFS 相比如何?
【BFS 了解什么是BFS,宽度优先搜索解释】两者都用于遍历图形,但它们的不同之处在于如何做到这一点 。BFS 在继续之前搜索给定深度级别的每个节点,而 DFS 在返回自身探索另一个分支之前访问尽可能深的节点 。DFS 通常使用堆栈数据结构而不是队列 。
- 电信卡能不能创建苹果id
- 千瓦时与安培小时:有什么区别?
- 4K与HD哪个更好?有何区别及高清有什么好处?
- 如何在Windows上运行Linux?设置详细教程
- 如何修复Win10中的打印机驱动程序错误0x80070705
- 如何修复Win10中的Xbox或商店错误0x87e0000d
- YouTube视频到MP3转换器:分步指南
- 如何在Zoom Call或会议中模糊背景
- 修复Windows10中的系统更新错误0x800F0816